몇 달 전 회사 팀원들끼리 진행하는 스터디에서 서비스 디스커버리에 대한 공유 글을 보고 MSA에 관심이 생겨 인프런을 통해 강의를 수강하고 있다. 앞으로 강의 내용을 파트별로 정리할 예정인데, 오늘은 MSA의 구성 요소 중 Service Discovery에 대한 내용을 정리하고자 한다.
MicroService Architecture
서비스 디스커버리를 이해하기 위해서는 흔히 줄여서 MSA라고 불리는 마이크로서비스 아키텍처에 대해 알아야 한다. 본 글은 MSA 자체에 대한 글이 아니기 때문에 MSA를 구성하는데 있어서 Service Discovery가 왜 있어야 하고 어떠한 역할을 하는지 정도만 파악할 수 있도록 정리하려고 한다.
MSA와 비교되는 대상으로 우리가 현재 회사에서 어플리케이션을 개발하는 방식인 Monolithic Architecture가 있다. Monolithic Architecture는 단어 그대로 소프트웨어의 모든 구성 요소가 한 프로젝트에 통합되어 있는 형태이다. 전체 소프트웨어가 하나로 관리되기 때문에 배포 및 테스트가 쉬우며 트랜잭션 관리도 용이하다는 장점이 있지만 프로젝트의 크기가 커질 수록 문제가 될 수 있다. 예를 들어 작은 기능을 수정하더라도 전체 서비스를 재 배포 한다거나, 특정 기능에 트래픽이 몰릴 경우 선택적으로 시스템을 확장하기 어렵다.
이러한 단점을 해결하기 위해 제시된 개념이 MicroService Architecture 이며 아래 그림에서 확인할 수 있듯이 소프트웨어를 각 기능별로 나누어 컴포넌트화 한뒤 각 컴포넌트의 상호 호출로 소프트웨어를 구성하는 방식이다.

그림에서 확인할 수 있듯이 각 서비스는 다른 장비에 올라가며 이로 인해 특정 기능을 수정한다면 해당되는 서비스만 재 배포하면 된다는 장점이 있으며, auto scale out 등의 확장성에 큰 장점을 가진다.
하지만 이러한 장점을 누리기 위해서는 각 서비스간 호출이 기반이 되는데, 어떠한 서비스에서 다른 서비스를 호출하기 위해서는 해당 서비스가 떠있는 서버의 ip, port를 알고 있어야 한다. MSA 환경에서는 auto scale out, 컨테이너 기반 배포 등을 통해 ip 정보가 쉽게 변경될 수 있는데, 이러한 각 서비스들의 ip, port를 관리하며 어떤 서비스를 호출할 때 호출 주소를 알려주는 기능을 하는것이 오늘 정리할 Service Discovery 이다.
Service Discovery
서비스 디스커버리(service discovery)는 서비스를 구성하는 개별 인스턴스를 찾는 프로세스이며, 서비스를 구성하는 다양한 노드 또는 엔드포인트를 지속적으로 추적한다. 이러한 서비스 디스커버리는 Client side, Server side discovery 두 가지 방법으로 구현할 수 있다.
Service Registry
사용가능한 Service의 목록을 관리하고, 서비스를 등록/해제/조회 할 수 있는 API를 제공하며 일종의 DB역할을 한다고 볼 수 있고 고가용성이 보장되어야 한다. 각 서비스는 이 api를 활용하여 기동 시에 자동으로 Service Registry에 등록되며 Service Registry는 지속적으로 서비스의 상태를 모니터링한다. Service Registry를 호출하는 주체에 따라 Client side, Server side Discovery로 나뉠 수 있으며, 대표적인 Service Registry로는 Netflix Eureka, Apache Zookeeper 등이 있다.
Client Side Discovery
서비스 클라이언트가 Service Registry를 직접 호출하여 서비스 위치를 찾은 뒤에 로드밸런싱 알고리즘을 통해 서비스를 호출하는 방식이다.

대표적으로 Netflix Eureka를 이용해 Service Registry를 구성하고, 이를 통해 얻은 서비스 호출 정보를 바탕으로 Netflix Ribbon을 통해 로드밸런싱된 요청을 하는 방식으로 구현할 수 있다. 이 방식은 비교적 간단하며, 서비스 별로 로드밸런싱 로직을 각각 구성할 수 있는 장점이 있으나, 서비스와 Service Registry간 직접적인 종속성이 생기며 서비스마다 각기 다른 언어를 사용한다면 각 언어별로 서비스 검색 로직을 구현해야 하는 단점이 있다.
Server Side Discovery
서비스 클라이언트가 직접 Servier Registry를 호출하지 않고 Platform router 혹은 로드밸런서(프록시)를 호출하는 방식이다. 이 때 요청을 받은 로드밸런서는 Service Registry를 호출하여 서비스의 위치를 알아내고 이를 기반으로 로드 밸런싱된 호출을 진행한다.

이 방식의 장점은 서비스 클라이언트가 직접 서비스 검색 로직을 구현할 필요가 없기 때문에 서비스 - Service Registry간 종속성을 제거할 수 있다는 것이다. 반면 단점으로는 로드밸런서라는 고가치 장비가 추가로 필요하게 된다는 점이 있다.
Netlfix Eureka를 이용한 간단한 Service Discovery 구현
앞서 정리한 내용을 직접 확인해보고 싶어 스프링 클라우드에서 채택한 Spring Cloud Netflix Eureka를 이용하여 간단한 Sevice Discovery를 구현해 보았다.
Eureka Server
먼저, 전체 서비스를 등록하고 조회, 관리할 수 있게 해주는 Eureka Server 프로세스를 기동해야 한다. 아래와 같이 프로젝트를 생성할 때 Eureka Server에 대한 의존성을 추가해주어도 되고, gradle에 직접 의존성을 추가해주어도 된다.
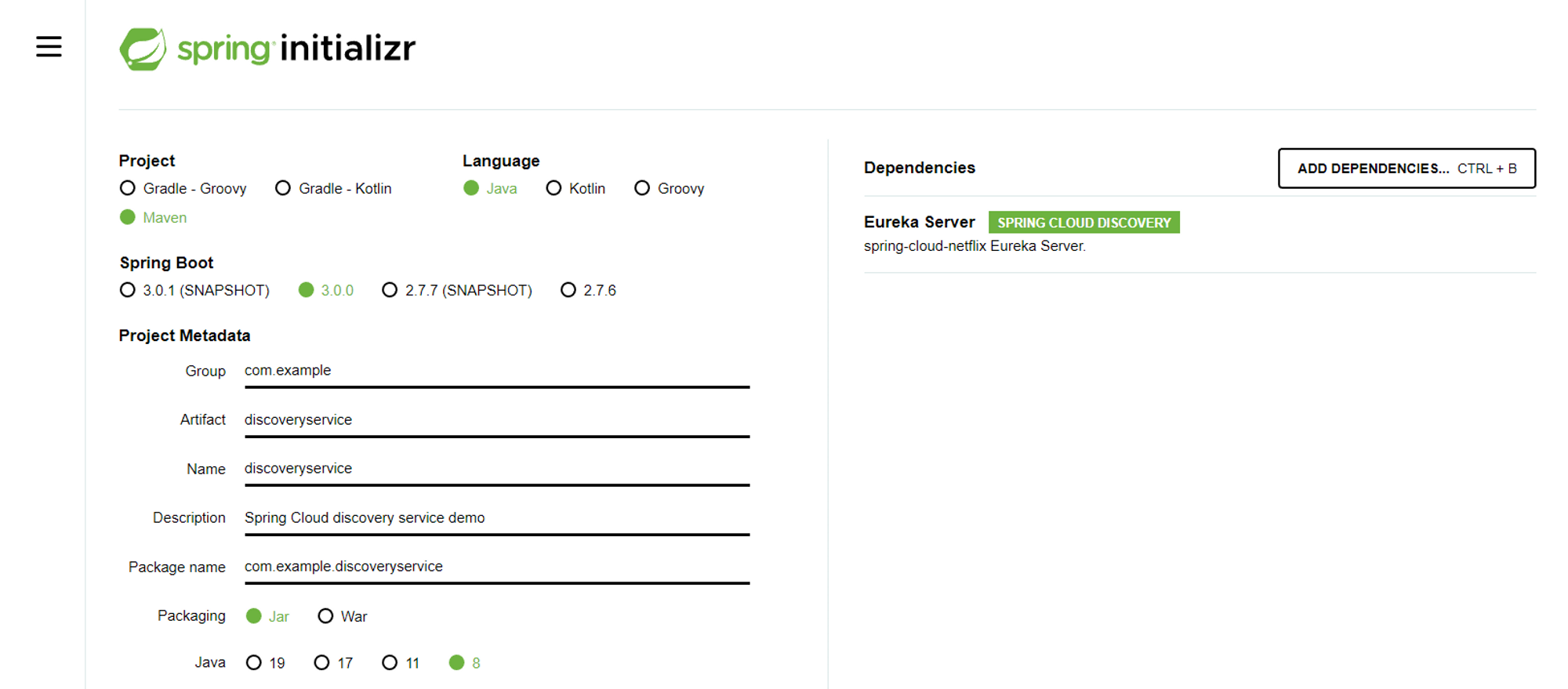
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-server'스프링 부트 어플리케이션을 실행하면 @SpringBootApplication 어노테이션을 찾고 해당 어노테이션이 붙은 빈 내부의 main 함수를 실행하게 된다. 예제상에서 이 프로세스는 다른 마이크로 서비스를 등록할 유레카 서버로 동작해야 하므로 해당 클래스에 @EnableEurekaServber 어노테이션을 붙여주어 유레카 서버로 동작할 수 있게 한다.
@EnableEurekaServer
@SpringBootApplication
public class DiscoveryApplication {
public static void main(String[] args) {
SpringApplication.run(DiscoveryApplication.class, args);
}
}유레카 서버 또한 일반 서비스처럼 서비스에 대한 몇 가지 설정이 필요한데, 이는 application.yml 파일에서 설정할 수 있다.
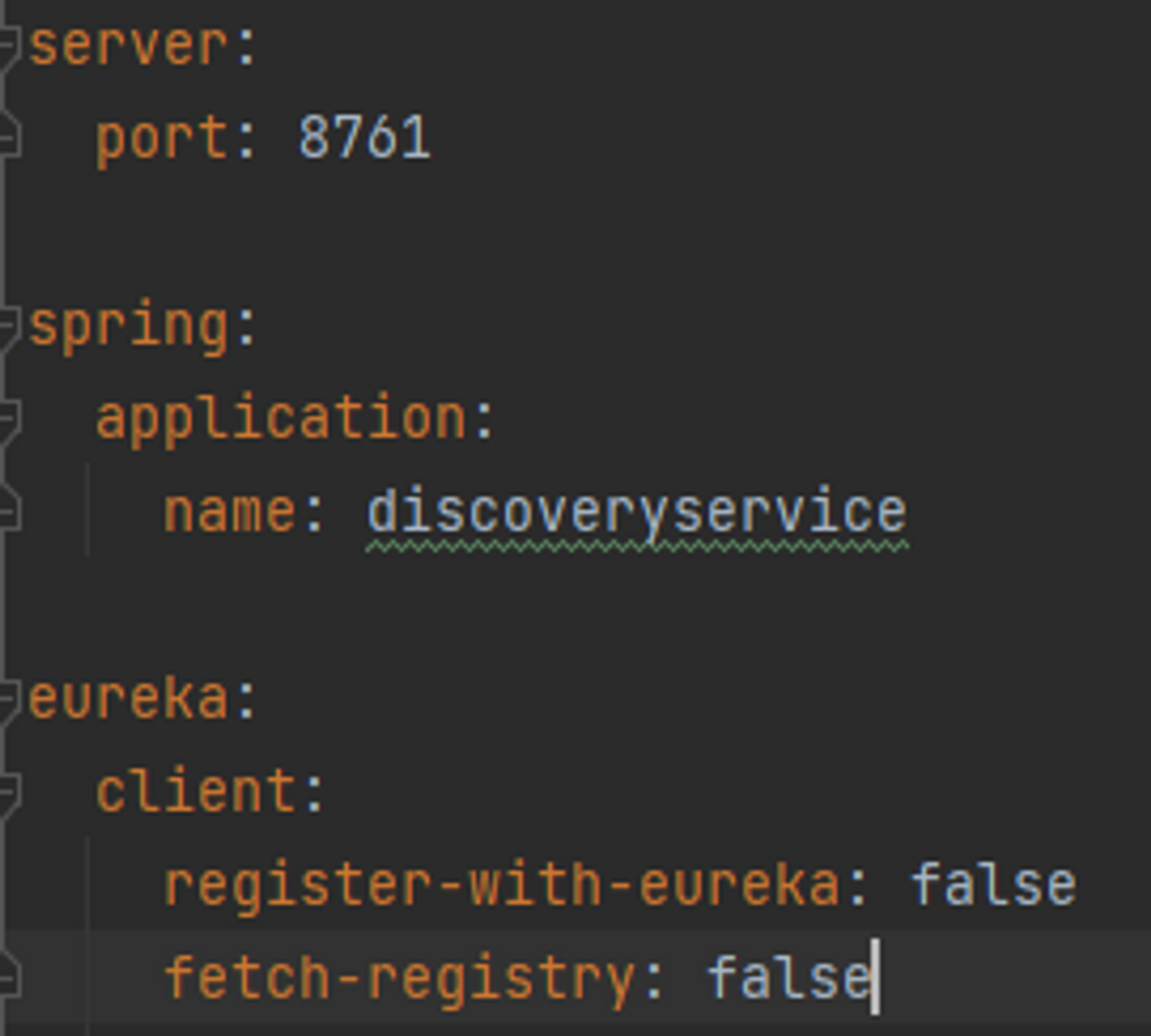
유레카 서버도 하나의 마이크로 서비스로 뜨는것이기 때문에 고유한 식별자가 필요한데, 이를 application.name으로 설정해준다. 추가로 eureka에 대한 설정도 해주어야 하는데 기본적으로 유레카 라이브러리가 포함되면 해당 프로세스는 client로 뜨려고 하기 때문에 유레카 서버에 등록하는 동작을 register-with-eureka: false로 두어 제한할 수 있다. 추가로 주기적으로 유레카 서버에 등록된 다른 서비스의 정보를 주기적으로 받아오는 fetch-registry 옵션도 false로 설정해 주어야 한다.

유레카 서버는 기본적으로 대시보드를 제공하므로 프로세스가 기동되면 ip:port를 웹 페이지에 입력하여 현재 유레카 서버의 상태를 조회할 수 있다.
Eureka Client
앞서 띄운 유레카 서버에 등록하기 위한 유저 마이크로 서비스를 생성한다. 유레카 서버에서는 @EnableEurekaServer 어노테이션을 사용했지만 이번에는 클라이언트로 동작할 것이므로 @EnableDiscoveryClient 어노테이션을 메인 어플리케이션 클래스 위에 추가해준다.
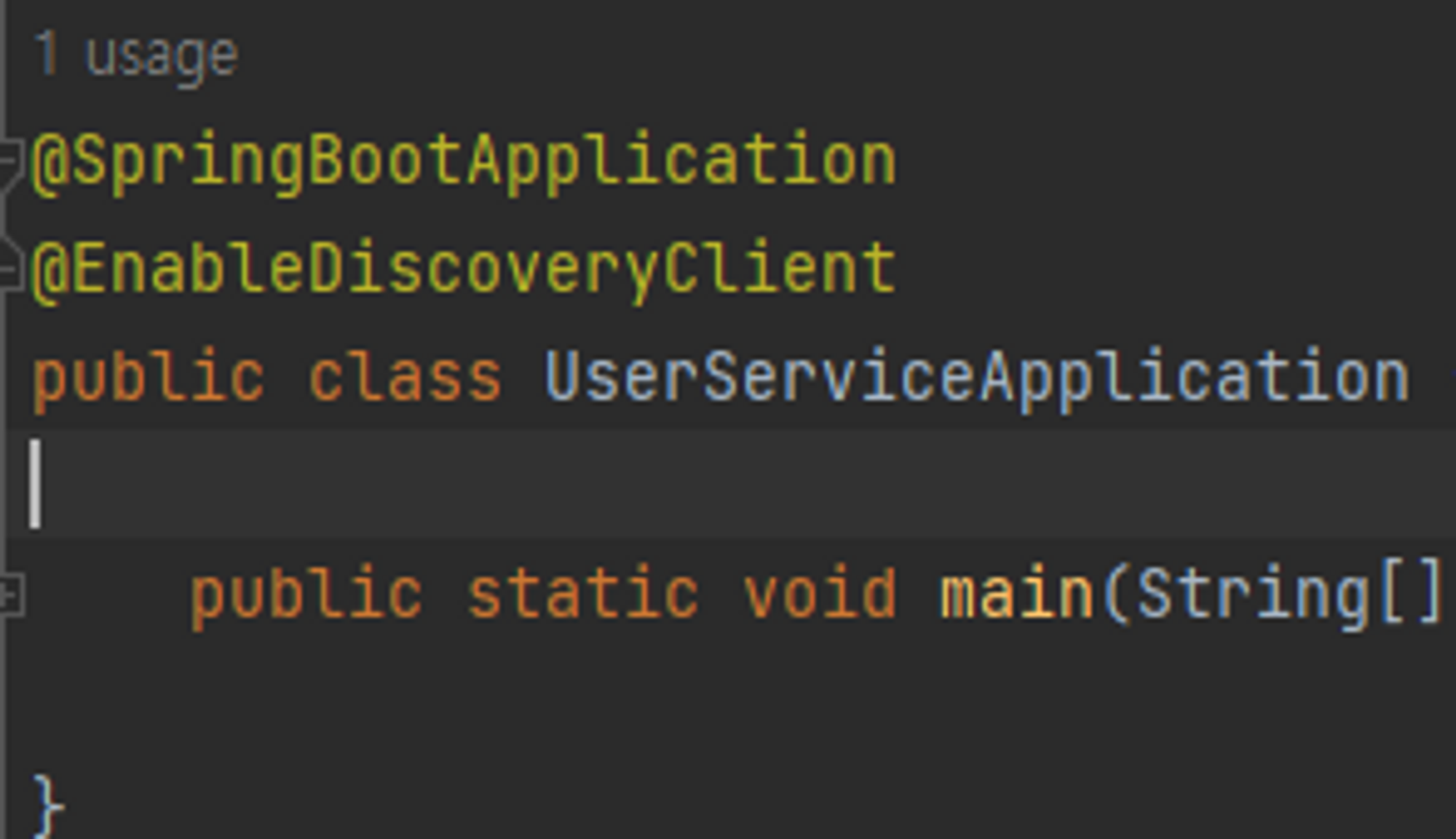
이번에는 프로세스가 클라이언트로 동작해야 하므로 application.yml파일 내부의 설정값도 유레카 서버와 다르게 설정한다.
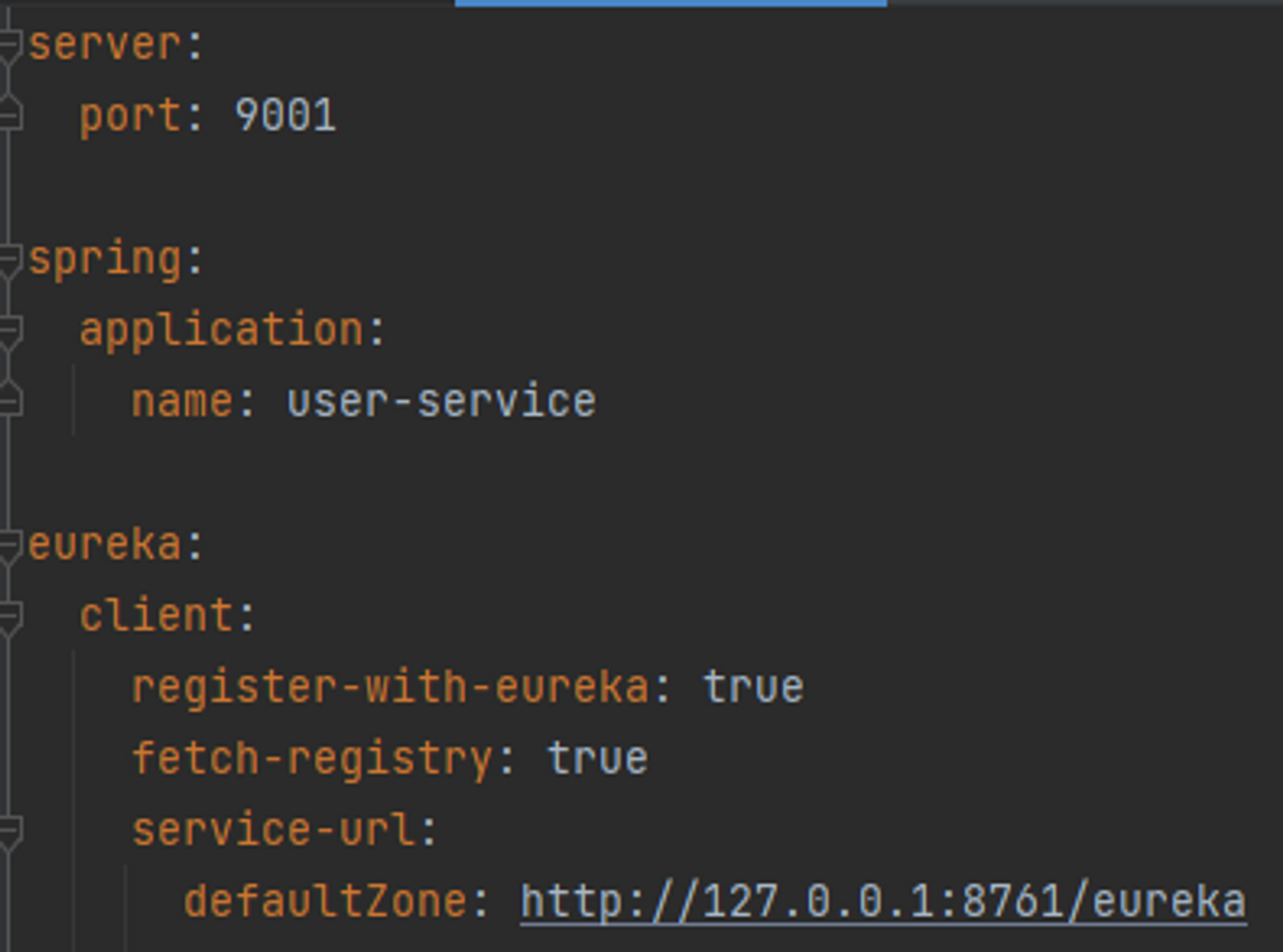
앞서 false로 설정했던 값들을 모두 true로 바꾸어주고, 해당 서비스가 등록될 유레카 서버의 주소를 service-url.defaultZone에 입력해준다. 이 값을 통해 유레카 클라이언트가 기동되면 자동으로 해당 주소에 대해 서비스 등록 요청을 하게 된다. 이 과정을 모두 완료한 뒤 프로세스를 실행하면 아래와 같이 유레카 서버 대시보드에서 등록된 서비스를 확인할 수 있다.
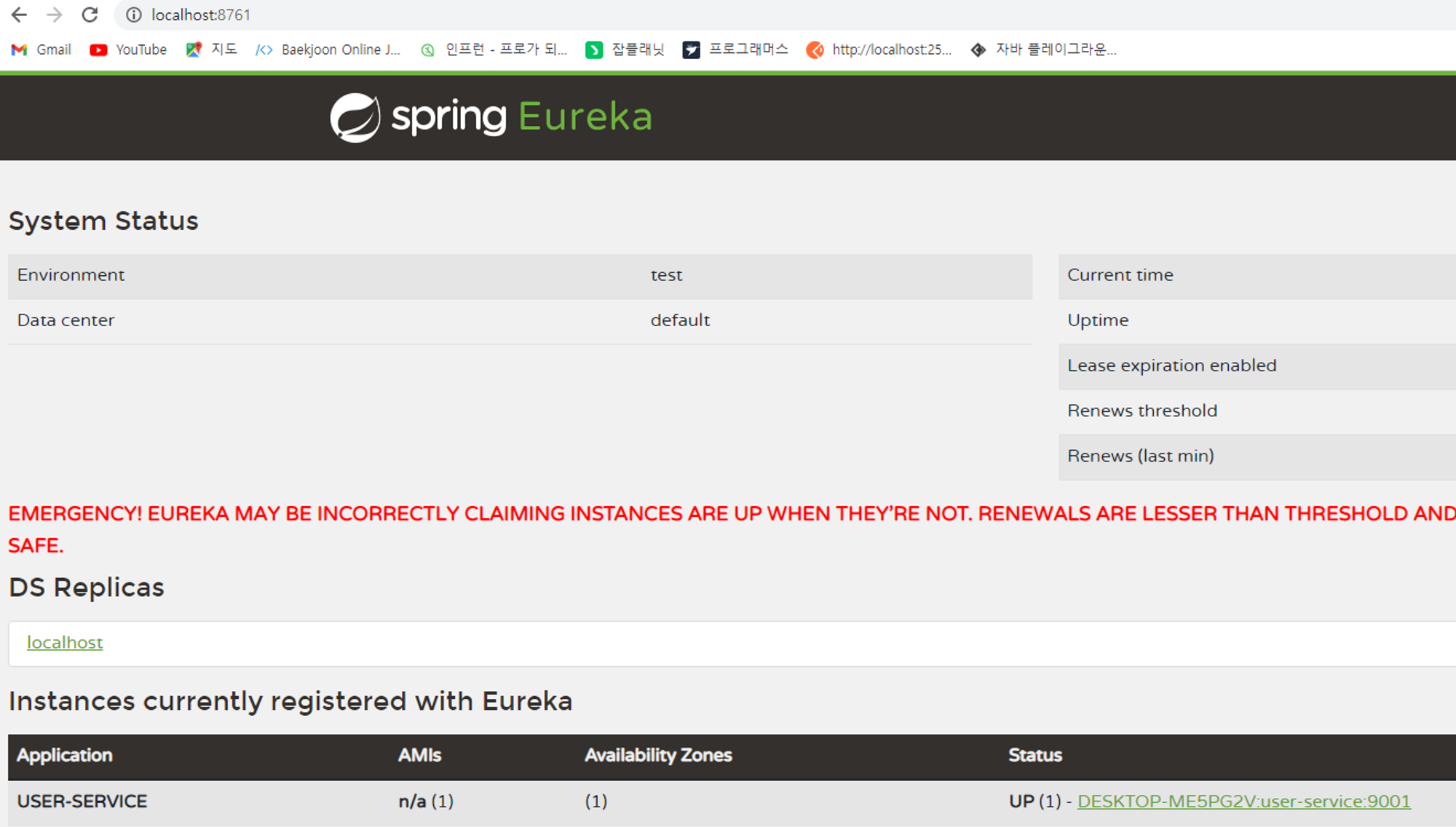
별도의 작업 없이 프로세스를 실행만 했는데도 유레카 클라이언트 프로세스가 자동으로 유레카 서버에 연결되었음을 확인할 수 있으며 여기서는 아래와 같은 점을 확인할 수 있다.
- 클라이언트에서 설정한 application.name으로 서비스가 식별되며 이 이름은 대, 소문자 구별을 하지 않고 대문자로만 표기된다.
- 클라이언트 서비스의 up, down 상태를 확인할 수 있다.
- 클라이언트의 ip, port를 조회할 수 있다.
여러 유레카 클라이언트 등록해보기
앞서 예제에서는 하나의 유레카 서버에 하나의 유저 서비스 유레카 클라이언트를 등록해 보았다. 실제 운영 환경에서는 유저 서비스를 여러개를 생성해서 등록할텐데 인텔리제이를 이용해 간단한 예제를 만들어 보았다.
동일한 코드로 프로세스 추가로 띄우기
테스트를 위해 또 다른 프로젝트를 생성하고 띄우기는 비효율적이므로 기존에 테스트에 사용한 서비스를 그대로 이용하여 프로세스만 하나 더 띄우려고 한다. 인텔리제이에서는 동일한 코드하도 application name을 다르게 등록하여 저장하면 다른 프로세스를 띄울 수 있다.

다만 이 경우에 모든 코드가 같기 때문에 프로세스 실행 시 port가 겹치게 된다. 이를 인텔리제이 설정을 통해 해결할 수 있는데, Ultimate 버전은 아래와 같이 VM Option을 주어 해결할 수 있다.
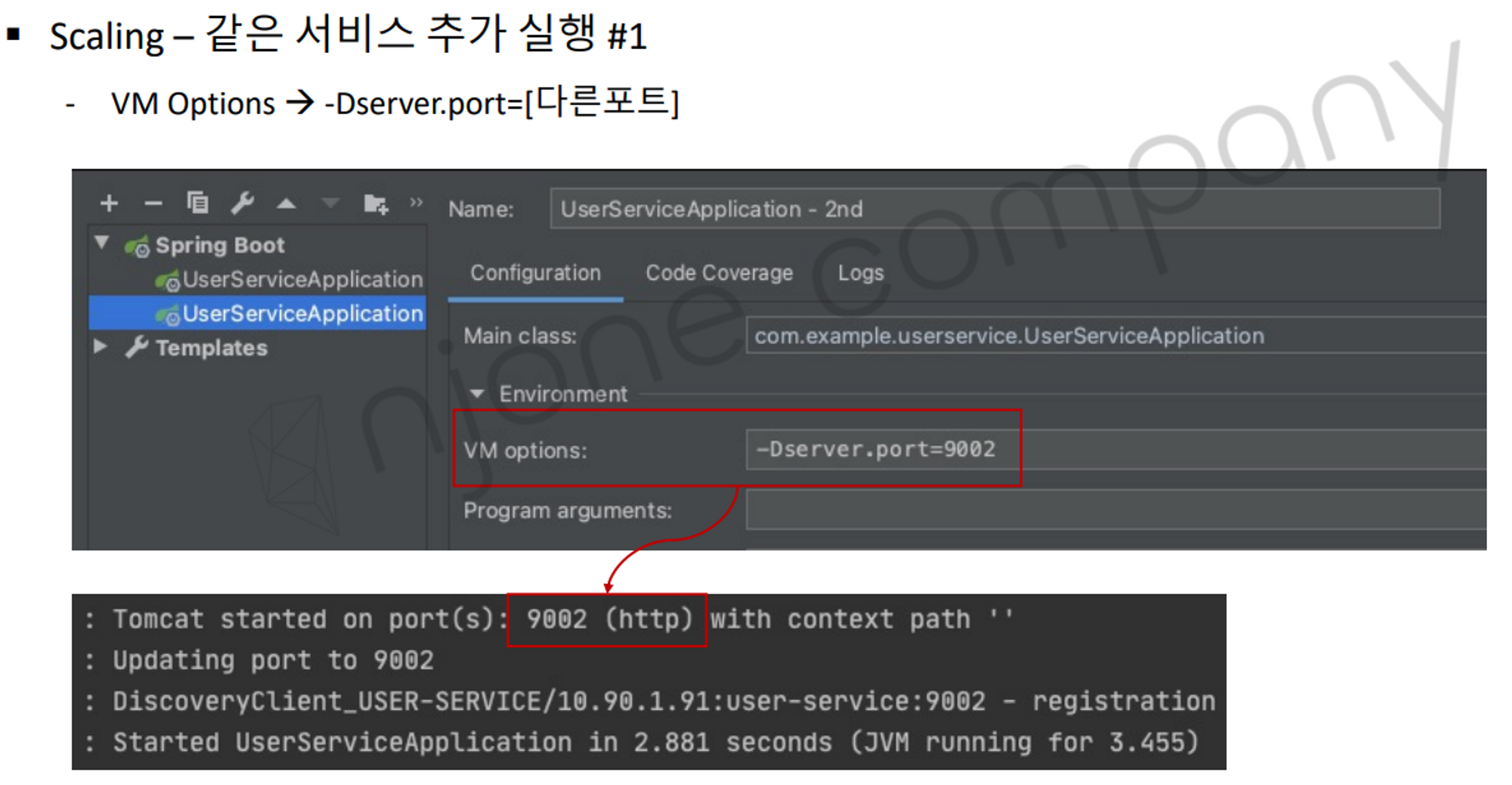
커뮤니티 버전은 위와 같은 설정창을 제공하지 않기 때문에 앞서 열였던 Run/Degug Configuration 설정 창에서 아래와 같이 server.port=[포트] 를 설정해주면 된다.

만약 이렇게 포트를 임의로 지정하기 번거롭다면 아래와 같이 application.yml 파일에서 포트 설정을 변경해주면 된다.
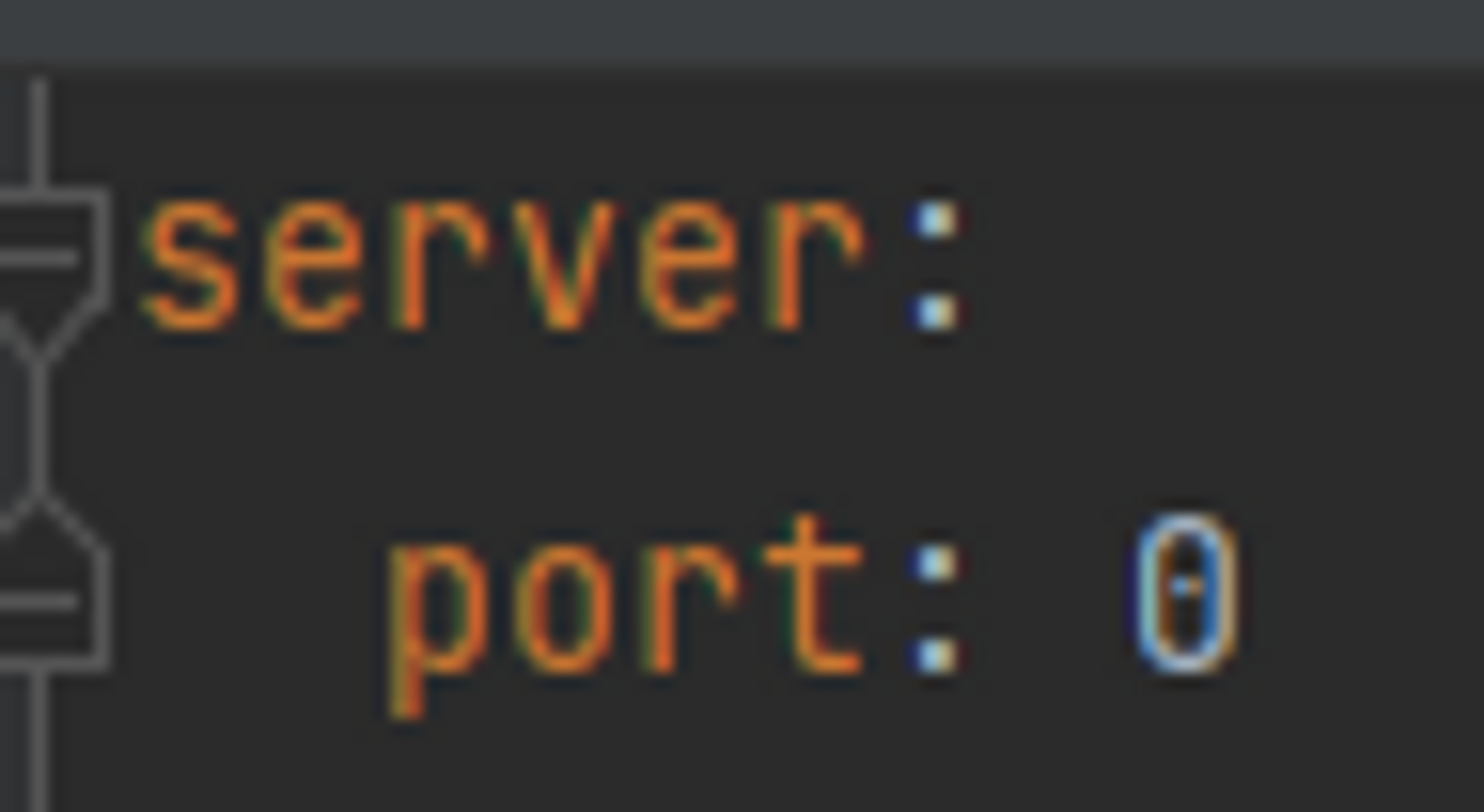
server.port:0 설정은 프로세스를 띄울때 마다 랜덤의 포트 번호를 사용하여 띄우게 된다.

Status 컬럼에서 보면 서비스의 포트가 0으로 보이지만 마우스 커서를 올리면 좌측 하단에서 실제 포트 번호를 확인할 수 있다.
각 인스턴스 구분하기
위의 대시보드 화면을 보면 분명 서비스 프로세스를 두 개 띄웠지만 한 개만 인식되는 것을 볼 수 있다. 이는 유레카 서버에서 클라이언트를 인식할 때 동적으로 부여된 port가 아닌, yml 파일에 설정된 port를 기준으로 식별하기 때문이다.
유레카 클라이언트는 port 외에 서비스를 식별할 수 있는 요소로 instance-id를 사용할 수 있는데, 설정 파일에서 이 값을 설정하여 각 인스턴스를 구분할 수 있게 한다.

위와 같이 설정 후 어플리케이션을 다시 띄우면 아래와 같이 부여된 인스턴스명에 의해 프로세스가 각각 식별되는 것을 확인할 수 있다.

정리
이번 글을 통해 MSA에서 가장 중요한 역할을 담당하는 Service Discovery에 대해 정리해볼 수 있었다. 이전에 스터디에서 공유해 주신 내용을 봤을 때에는 정확히 이해하지 못하고 겉도는 느낌이었는데 직접 코드를 실행해보고 정리해보면서 확실히 이해할 수 있던것 같다.
이후로 다른 MSA의 구성 요소에 대해서 정리하고 실제 코드를 통해 배운점들을 글로 정리해서 기록하고, 공유하면 좋을 내용들은 회사 스터디를 통해 팀원들에게 공유할 예정이다.
참고
'Java' 카테고리의 다른 글
| [Java] Spring Boot Actuator (0) | 2023.02.14 |
|---|---|
| [Spring Cloud] HA of Service Discovery (0) | 2023.02.07 |
| Jackson 라이브러리의 직렬화/역직렬화 (0) | 2022.09.21 |
| 제네릭을 이용한 마이바티스 쿼리 유틸 만들어보기 (0) | 2022.09.13 |
| GC 개념 및 동작 원리 (0) | 2022.09.13 |




댓글