Service Discovery의 고가용성

지난 글에서는 MSA에서 각 마이크로 서비스의 위치를 기억하고, 각 서비스가 다른 서비스의 위치를 조회할 수 있게 DB 역할을 해주는 Service Discovery에 대해 정리해 보았다. 이 주제는 나 뿐만 아니라 함께 스터디를 진행하고 있는 팀원도 다룬적이 있었는데, 당시에 했던 여러 질문 중 ‘만약 Service Registry에 장애가 발생한다면 전체 시스템에 영향을 줄 수 있을것 같은데 이에 대한 대비책이 있는지’ 라는 질문이 있던 것으로 기억한다.
각 서비스 간 통신을 통해 거대한 어플리케이션을 이루는 MSA 특성 상, 각 서비스의 위치를 저장하는 Serviece Discovery에 장애가 생긴다면 그 장애가 서비스 전체로 번지게 된다. 따라서 앞서 언급한 질문에 대한 조치로 어떤 것이 있을지 궁금했었고, 오늘 그 내용에 대해 정리하고자 한다.
고가용성
고가용성이란 서버와 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질을 말한다. 고가용성이란 "가용성이 높다"는 뜻으로서, "절대 고장나지 않음"을 의미한다.
개발과 관련한 이야기를 할때 흔히 고가용성이라는 단어를 쓰곤 한다. 어플리케이션의 모든 구성 요소가 중요하지만 위의 경우처럼 단 하나의 구성 요소의 장애가 시스템 전체로 번질 수 있을 경우, 해당 구성 요소는 고가용성이 보장되어야 한다. 고가용성의 사전적 정의는 위와 같고, 핵심 단어를 추리면 ‘오랜 기간 지속적으로 정상운영’이 가능해야 한다. 지난 글에서 예로 들었던 Netflix Eureka의 경우에는 아래와 같은 두 요소를 통해 고가용성을 보장하고 있다.
- Client Side Caching: Eureka Client는 추가적인 설정 없이 Eureka Server로부터 받아온 registry information을 캐싱한다. 만약 모든 Eureka Server가 가용하지 않은 상태가 되더라도 클라이언트는 registry의 마지막 정상 스냅샷을 보유하기 때문에 완벽하진 않지만 가용성을 보장할 수 있다.
- Server Cluster: Eureka Server는 서버들의 Cluster로 구성될 수 있다. 만약 하나의 Eureka Server가 가용하지 않게 되더라도 클라이언트는 또 다른 Eureka Server에 접근할 수 있기 때문에 가용성을 보장할 수 있다.

클러스터는 여러 개의 Eureka Server 인스턴스로 구성되며, 각 서버는 peer라고 불린다. 이러한 peer들이 실행되면 자동으로 서로간 synchronize registraions를 진행하게 되며 이를 peer awareness라고 한다. 이러한 상호 인식 과정을 그림으로 나타낸 것이 위 그림이며, 이렇게 구성된 클러스터 중 하나의 peer가 내려가더라도 Client는 아래 그림과 같이 지속적으로 레지스트리 정보를 요청할 수 있다.

보통 클라이언트는 같은 Region에 속한 Eureka Server에 요청을 보내게 되지만, 위와 같이 요청을 보내던 Peer1이 다운되면 다른 Region에 위치한 Cluster Server에 요청을 할 수 있게 되어 고가용성을 보장할 수 있게된다.
Eureka Server Cluster 구성해보기
Eureka Server 설정
spring:
config:
activate:
on-profile: "peer-1"
application:
name: eureka-server-clustered
server:
port: 9001
eureka:
instance:
hostname: peer-1-server.com
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://peer-2-server.com:9002/eureka/,http://peer-3-server.com:9003/eureka/
---
spring:
config:
activate:
on-profile: "peer-2"
application:
name: eureka-server-clustered
server:
port: 9002
eureka:
instance:
hostname: peer-2-server.com
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://peer-1-server.com:9001/eureka/,http://peer-3-server.com:9003/eureka/
---
spring:
config:
activate:
on-profile: "peer-3"
application:
name: eureka-server-clustered
server:
port: 9003
eureka:
instance:
hostname: peer-3-server.com
client:
registerWithEureka: true
fetchRegistry: true
serviceUrl:
defaultZone: http://peer-1-server.com:9001/eureka/,http://peer-2-server.com:9002/eureka/예제에서는 클러스터를 총 3개의 유레카 서버로 구성할것이기 때문에 총 3개의 설정값을 준비한다. 3개 profile 모두 아래와 같이 공통의 속성을 갖고 있다. 참고로 spring.config.activate.on-profile: {프로필}은 Spring boot 2.4부터 변경된 profile 설정 방식이다.
- eureka.client.registerWithEureka: true ⇒ 서버가 실행되었을 때 자동으로 Eureka 서버에 등록(꼭 클라이언트 뿐만 아니라 서버도 이 설정을 통해 상호간 등록이 가능하다.)
- eureka.client.fetchRegistry: true ⇒ Eureka 서버로부터 서비스 리스트 정보를 자신의 local에 캐싱(default 30초)
- eureka.client.serviceUrl ⇒ 자동 등록될 Eureka 서버의 정보
유레카 서버로 설정하기
@SpringBootApplication
@EnableEurekaServer
public class DiscoveryserviceApplication {
public static void main(String[] args) {
SpringApplication.run(DiscoveryserviceApplication.class, args);
}
}이렇게 준비된 세 개의 인스턴스를 Eureka Server로 띄워 클러스터링을 할 것이기 때문에 @EnableEurekaServer 어노테이션을 붙여주어야 한다.
hosts 추가
127.0.0.1 peer-1-server.com
127.0.0.1 peer-2-server.com
127.0.0.1 peer-3-server.com유레카 서버가 서로 다르게 인식되기 위해서는 호스트 이름이 달라야 한다. 따라서 hosts 파일을 열어 위와 같이 host 정보를 추가해 준다.
서버 띄우고 확인해보기
위와 같이 생성한 프로젝트에서 profile 값을 peer-1, 2, 3으로 각기 다르게 실행하면 내장 톰캣 로그를 통해 자동으로 상호간 연결을 하는것을 확인해볼 수 있다.


또한 Eureka Server에서 기본적으로 제공해주는 Dashboard에 접근해보면(http://peer-3-server.com:9001/) 아래와 같이 각 peer가 잘 등록된 것을 확인해볼 수 있다.
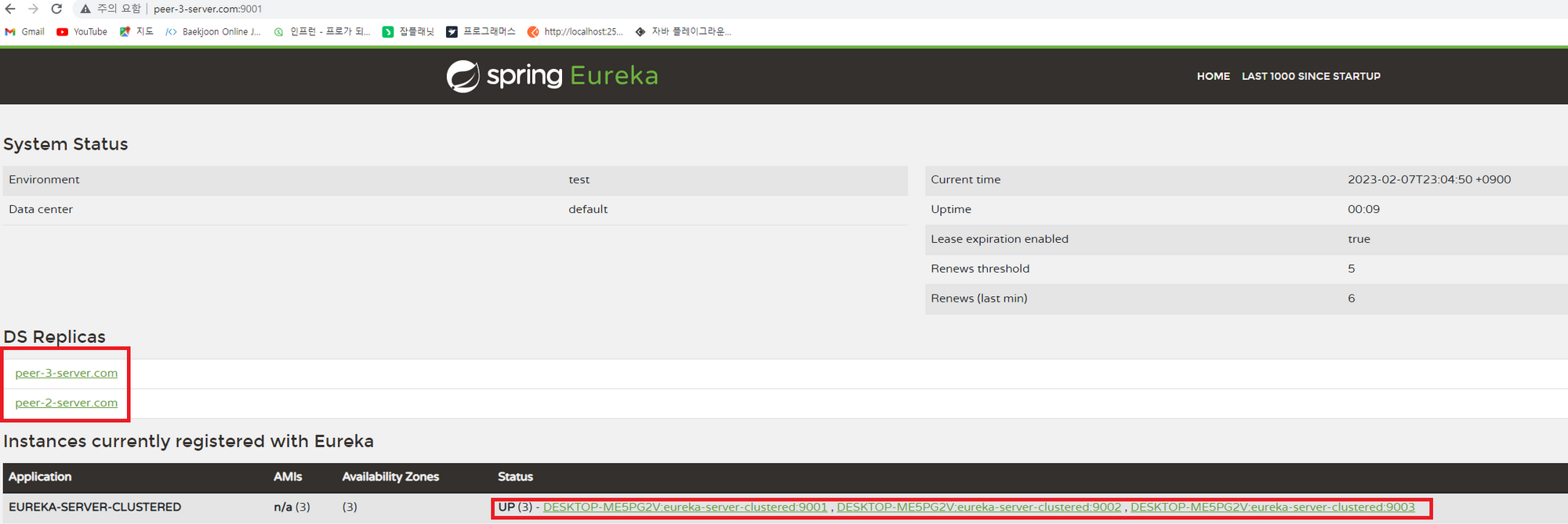
Eureka Client 띄우기
eureka:
client:
serviceUrl:
defaultZone: http://peer-1-server.com:9001/eureka, http://peer-2-server.com:9002/eureka, http://peer-3-server.com:9003/eureka유레카 클라이언트를 구동하는 방법은 지난 글에 정리해놓았으므로 변경되는 부분만 정리한다. 클라이언트가 구동되었을 때 등록될 Eureka Server의 정보를 eureka.client.serviceUrl.defaultZone에 적어주어야 하는데, 이 경우는 서버가 Cluster 구조이므로 각 클러스터 서버의 주소를 전부 적어준다.
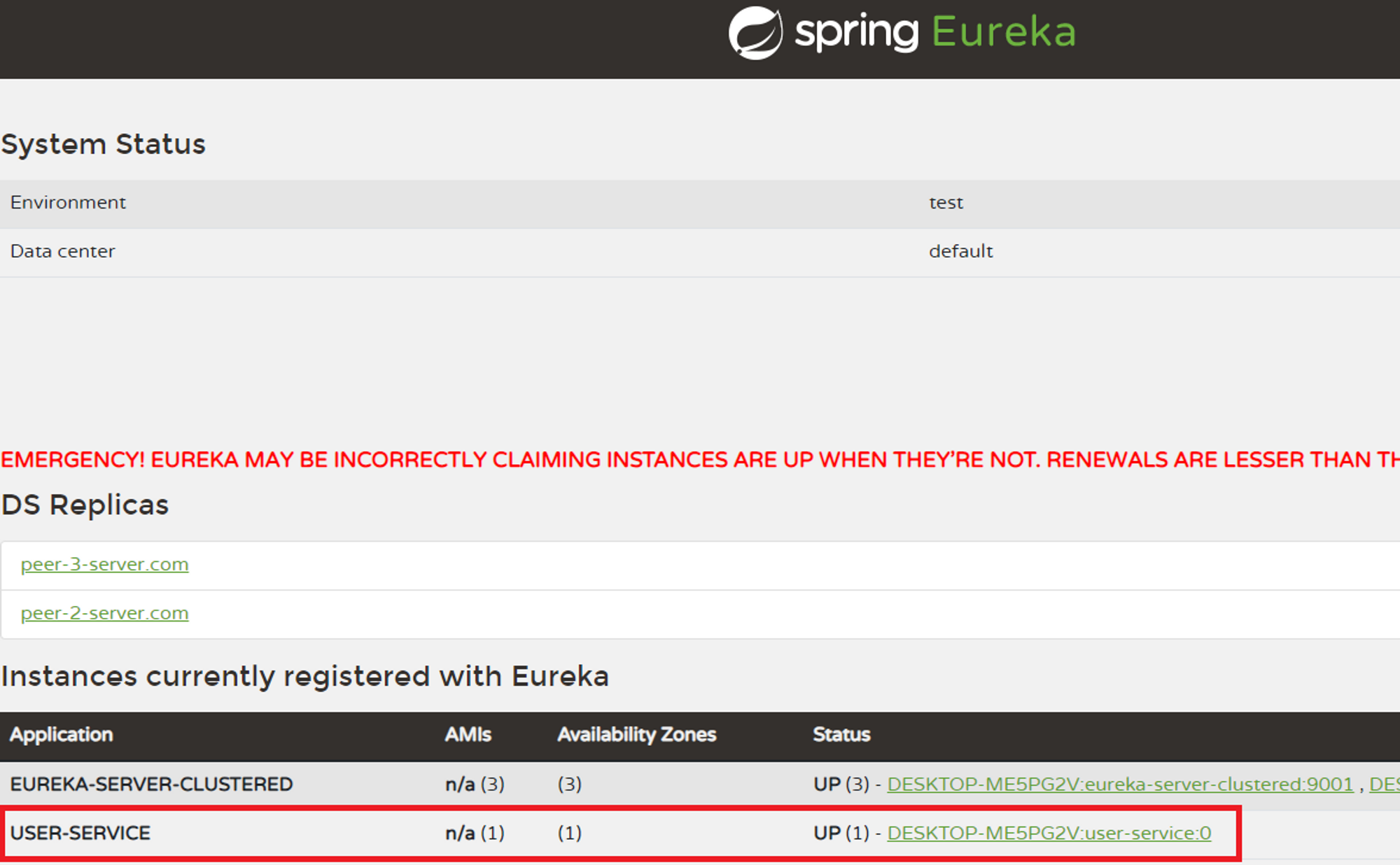
정리
MSA에서 중요한 역할을 담당하는 Service Discovery의 고가용성을 보장할 수 있는 방법에 대해 정리해보고, 간단한 예제를 통해 그 방법 중 하나인 Eureka Server Cluster를 구성해 보았다. Service Discovery에 대한 이론만 공부했을 때에는 실무와 연관짓기가 어려웠는데, 실무에서 중요한 고가용성과 관련된 사항을 학습하고 나니 작게나마 프로젝트를 시작해서 직접 유레카 클러스터를 구성하여 사용해보고 싶어졌다.
현재 수강하고 있는 MSA 관련 강의를 듣고 강의에서 실습하는 예제에 유레카 서버 클러스터를 적용해 보고 추후 정리하여 공유해보고 싶다.
참고
Service Discovery in a Microservices Architecture - NGINX
Explore the service discovery within a microservices architecture, including client-side and server-side discovery patterns, the service registry, & more.
www.nginx.com
Spring Cloud: High Availability for Eureka
Setup a Resilient Eureka Server Cluster
medium.com
Eureka_2 - guide
Eureka Server 추가, 변경, 삭제가 일어날 때 Eureka Client가 얼마나 자주 service urls를 갱신할 것인지 eureka.client.eureka-service-url-poll-interval-seconds 값으로 조정할 수 있다 (default: 0, 단 DNS를 통해 service urls를
coe.gitbook.io
'Java' 카테고리의 다른 글
| Cursor<T> (0) | 2023.03.09 |
|---|---|
| [Java] Spring Boot Actuator (0) | 2023.02.14 |
| [Spring Cloud] Service Discovery (0) | 2023.01.22 |
| Jackson 라이브러리의 직렬화/역직렬화 (0) | 2022.09.21 |
| 제네릭을 이용한 마이바티스 쿼리 유틸 만들어보기 (0) | 2022.09.13 |




댓글